
[ad_1]
Head over to our on-demand library to view sessions from VB Transform 2023. Register Here
A Harvard-led study has found that using generative AI helped hundreds of consultants working for the respected Boston Consulting Group (BSG) complete a range of tasks more often, more quickly, and at a higher quality than those who did not use AI.
Moreover, it showed that the lowest performers among the group had the biggest gains when using generative AI.
The study, conducted by data scientists and researchers from Harvard, Wharton, and MIT, is the first significant study of real usage of generative AI in an enterprise since the explosive success of ChatGPT’s pubic release in November 2022 — which triggered a rush among major enterprise companies to figure out optimal ways to utilize it. The researchers moved quickly, starting their research in January of this year, and using GPT-4 for the experiment — which is widely considered the most powerful large language model (LLM). The study carries some significant implications for how businesses should approach deploying it.
“The fact that we could boost the performance of these highly paid, highly skilled consultants, from top, elite MBA institutions, doing tasks that are very related to their every day tasks, on average 40 percent, I would say that’s really impressive,” Harvard’s Fabrizio Dell’Acqua, the paper’s lead author, told VentureBeat.
Event
VB Transform 2023 On-Demand
Did you miss a session from VB Transform 2023? Register to access the on-demand library for all of our featured sessions.
The report was released for public review nine days ago, but did not get significant attention beyond the academic industry and their social circles.
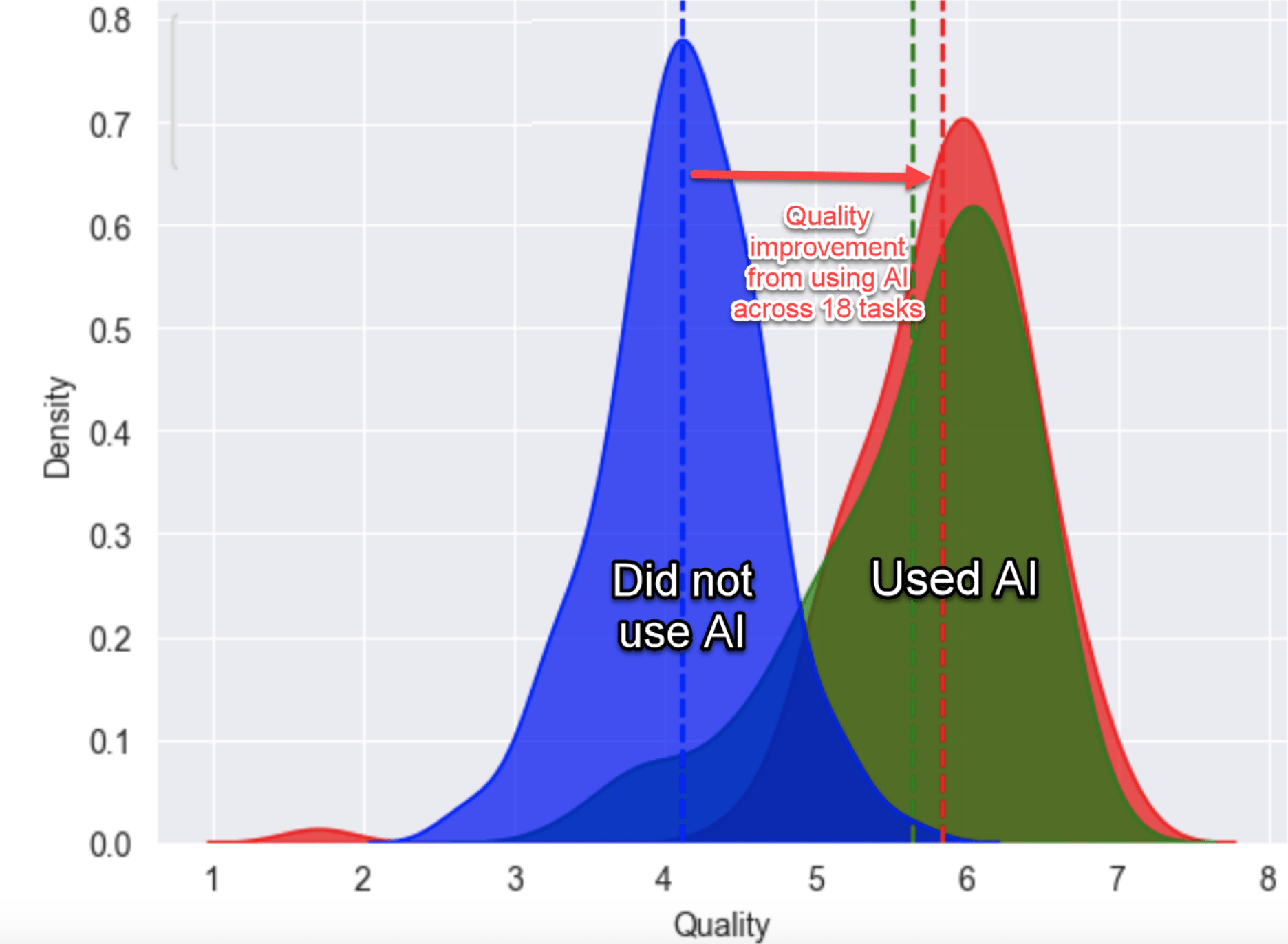
The report is the latest research confirming that generative AI will have a profound impact on workforce productivity. Aside from its headline, the research provided some cautionary findings about when not to use AI. It concluded that there is what it called a “jagged technology frontier,” or a difficult to discern barrier between tasks that are easily done by AI, and others that are outside AI’s current capabilities.
That frontier is not only jagged, it is constantly shifting as AI’s capabilities improve or change, said Francois Candelon, the senior partner at BCG responsible for running the experiment from the BCG side, in an interview with VentureBeat. This makes it more difficult for organizations to decide how and when to deploy AI, he said.
The study also pointed to two emerging patterns of AI usage by some of the firm’s more technology-competent consultants — which the researchers labeled the “Cyborg” and “Centaur” behaviors — that the researchers concluded may show the way forward in how to approach tasks where there’s uncertainty about AI’s capabilities. We’ll get to that in a second.
The study is the first to research enterprise usage of AI at scale, among professionals on real day-to-day task
The study included 758 consultants, or 7 percent of the consultants at the company. For each one of the 18 tasks that were deemed within this frontier of AI capabilities, consultants completed 12.2 percent more tasks on average, and completed tasks 25 percent more quickly, than those who did not use AI. Moreover, the consultants using AI — the study equipped them with access to GPT-4 — produced results with 40 percent higher quality when compared to a control group that did not have such access.
“The performance improved on every dimension. Every way we measured performance,” wrote another contributor to the study, Ethan Mollick, professor at the Wharton School of the University of Pennsylvania, in his summary of the paper.
The researchers first established baselines for each of the participants, to understand how they performed on general tasks without using GPT-4. The researchers then asked the consultants to do a wide variety of work for a fictional shoe company, work that the BCG team selected in order to try to accurately represent what consultants do.
GPT-4 is a skill leveler on many key, high-level tasks
The types of tasks were organized into four main category types: creative (for example: “Propose at least 10 ideas for a new shoe targeting an underserved market or sport.”), analytical (“Segment the footwear industry market based on users.”), writing and marketing related (“Draft a press release marketing copy for your product.”), and persuasiveness oriented (“Pen an inspirational memo to employees detailing why your product would outshine competitors.”).
One of the more interesting findings was that AI was a skill leveler. The consultants who scored the worst on their baseline performance before the study saw the biggest performance jump, 43%, when they used AI. The top consultants got a boost, but less of one.
But the study found that people who used AI for tasks it wasn’t good at were more likely to make mistakes, trusting AI when they shouldn’t.
One of the study’s major conclusions was that AI’s inner workings are still opaque enough that it’s hard to know exactly when it is reliable enough to use for certain tasks. This is one of the major challenges for organizations going forward, the study said.
Centaur and Cyborg behaviors may show the way forward
But some consultants appeared to navigate the frontier better than others, the report said, by acting as what the study called “Centaurs” or “Cyborgs,” or moving back and forth between AI and human work in ways that combined the strengths of both. Centaurs worked with a clear line between person and machine, switching between AI and human tasks, depending on the perceived strengths and capabilities of each. Cyborgs, on the other hand, blended machine and person on most tasks they performed.
“I think this is the way work is heading, very quickly,” wrote Wharton’s Mollick.
Still, the wall between what tasks can really be improved with AI remains invisible. “Some tasks that might logically seem to be the same distance away from the center, and therefore equally difficult – say, writing a sonnet and an exactly 50 word poem – are actually on different sides of the wall,” said Mollick. “The AI is great at the sonnet, but, because of how it conceptualizes the world in tokens, rather than words, it consistently produces poems of more or less than 50 words.”
Similarly, some unexpected tasks (like idea generation) are easy for AIs while other tasks that seem to be easy for machines to do (like basic math) are challenges for LLMs, the study found.
AI’s promise can induce humans to fall asleep at the wheel
The problem is that humans can overestimate AI’s competence areas. The paper confirmed other earlier research done by Harvard’s Dell’Acqua that showed trust in AI competence can lead to a dangerous over reliance on it by humans, and lead to worse results. In an interview with VentureBeat, Dell’Acqua said users essentially “switch off their brains” and outsource their judgment to AI. Dell’AAcqua coined this “falling asleep at the wheel” in a key study in mid-2021, where he found that recruiters using AI to find applicants became lazy and produced worse results than if they hadn’t used AI.
The latest study also found AI can produce homogenization. The study looked at the variation in the ideas presented by subjects about new market ideas for the shoe company, and found that while the ideas were of higher quality, they had less variability than those ideas produced by consultants not using AI. “This suggests that while GPT-4 aids in generating superior content, it might lead to more homogenized outputs,” the study found.
How to combat AI-driven homogeneity
The study concluded that companies should consider deploying a variety of AI models — not just Open AI’s GPT-4, but multiple LLMs — or even increased human-only involvement, to counteract this homogenization. This need may vary according to a company’s product: Some companies may prioritize high average outputs, while others may value exploration and innovation, the study said.
To the extent that many companies are using the same AI in a competitive landscape, and this results in reduced uniformity of ideas, companies generating ideas without AI assistance may stand out, the study concluded.
BCG’s Francois Candelon said the study’s findings around homogeneity risks will also force organizations to make sure they keep collecting clean, differentiated data for use in their AI applications. “With Gen AI, it’s even more urgent to not only make sure you have clean data… but try to find ways to collect it. To a certain extent, this will become one of the keys to differentiation.”
OpenAI’s ChatGPT, Google’s Bard, Anthropic’s Claude, and a host of other open-source LLM platforms, including Meta’s Llama, are increasingly allowing companies to customize their results by injecting their own proprietary data into the models, so that they can improve not only accuracy, but specialization and differentiation in specific fields.
BCG’s Candelon said the study is playing a major factor in the firm’s decision-making about how to use AI internally. Yes, the study found that AI has a surprising ability to offer specialized knowledge, and concluded the effects of AI are expected to be higher on the most creative, highly paid, and highly educated workers. As such, it leveled up the performance of the poorest performers at BCG. However, Candelon said the skill levels of the BCG consultants are relatively homogenous when compared to the general population, and so the difference in performance between the poorest and best performers wasn’t too large. Thus, he didn’t think the study suggested the firm could start hiring people with almost no training in consulting or strategy work.
More studies will investigate which tasks are better for Centaur and Cyborg behaviors
The study confirmed that certain tasks will consistently be better performed by AI, and this flies in the face of some current practices, Candelon said. Candelon said companies shouldn’t make the mistake of concluding AI is best for generating as a first draft, and forcing humans to always come into enhance. He said companies should do the opposite: “You let AI do what it is really great at, and humans should try to go outside of this frontier and really deep dive and dedicate their time to the other tasks.”
He said the Centaur’s behavior is notable, because Centaurs have learned to dedicate some tasks to AI, for example the summarizing of interviews and other creative tasks, while dedicating their own focus to things more relevant for human competence – for example task related to data or change management. However, he said the firm plans to investigate the Centaur and Cyborg behaviors more, because in some instances it may be better to be a Cyborg, mixing human and AI competencies together.
As for writing up reports on AI research like what I’m doing here, with interviews of the researchers about their views on the report’s conclusions, I think the jury is still out on whether machines are better than humans. How did I do?!
VentureBeat’s mission is to be a digital town square for technical decision-makers to gain knowledge about transformative enterprise technology and transact. Discover our Briefings.
[ad_2]
Source link





